- Published on
A Human-centric Approach to Fairness in AI
- Authors

- Name
- Timothy Lin
- @timlrxx
Table of Contents
Background
After 4+ years implementing data science solutions, I find myself confronting a familiar set of challenges in which I started my career in - policy evaluation. While this is in the sphere of AI fairness, there are many similar parallels across both domains.
This post is written as part of our participation in the Monetary Authority of Singapore (MAS) Veritas challenge on applying fairness, ethics, accountability and fairness (FEAT) in artificial intelligence and data analytics (AIDA) use cases.^[For more information, please refer to the challenge press release and the recommended assessment methodology.]
As one of the shortlisted finalist, I thought it would be good to blog about the approach we are taking and why we believe it to be the right one. In the initial written proposal, rather than simply pitching our existing experience and expertise, I decided to write an aspirational proposal of what fairness in machine learning could look like, which I feel is very different from what it currently is in practice. I thank the MAS and organising committee for giving us the opportunity to shape some of the most important policy guidelines and recommendations in the space.
Our proposal is novel in a few ways:
It is an open-source solution. We are transparent by design. It strikes me as odd that methods to evaluate whether a model is fair or not is shrouded in secrecy by commercial companies.1
We do not make ethical judgements of what is fair. We believe that in the issue of fairness there is no one metric to rule them all. Rather a deliberative and consultative process is essential. Though having made a decision, we can make subsequent workstream processes as easy as possible.
We embed the evaluation of AI fairness within the best practices of machine learning development and operations such as version control, unit testing and continuous integration.
It has been a fun few weeks exploring the latest thinking of scholars in this field and listening to the masterclass sessions provided by the industry partners. In the spirit of openness, I decided to document my thought process in designing the described framework. This is the first post in a series of three.
For the first post, I will focus on the issue of fairness and argue that the right approach that should be adopted by the industry is a human-centric one. Attempts to distil fairness down to a single metric are unhelpful and counter-productive. As business owners and model developers we should embrace the struggle in trying to define fairness in relation to the problem we are trying to solve, the models that we are using, and the broader societal context, rather than shun it.
The case for a single fairness metric
Having a single metric to quantify what is fair or not seems to be a goal for many AI scholars in the field, as well as many of industry practitioners. After all, while methods might vary, the foundation of machine learning hinges on maximising or minimising clear objectives2. A business problem can then be translated to a mathematical / statistical / computational problem and different methods can be compared against each other based on how far the predicted output differs from the actual output as measured by the objective function.
If fairness could be distilled down to a single metric, a data scientist can include it as part of the objective function or as a constraint and find an ideal point that maximises overall business needs while satisfying fairness requirements.
A brief survey of fairness metrics
Barocas et al. (2019) lists 19 demographic fairness criteria for classification problems. This includes measures such as Demographic Parity / Statistical Parity (Dwork et al., 2012), Equalized Odds Metric (Hardt et al., 2016) and Calibration within Groups (Chouldechova, 2017). They are all statistical measures derived from the predictions of a classification model and differ in terms of which element(s) of the confusion matrix they are trying to test for equivalence.
In another survey of fairness definitions, Verma & Rubin (2018) listed 20 definitions of fairness, 13 belonging to statistical measures, 3 being classified as similarity-based measures and the remaining 4 stemming from causal reasoning. Applying a logistic regression to a German credit dataset, they showed that approximately half of their definitions are satisfied while the other half are not satisfied:
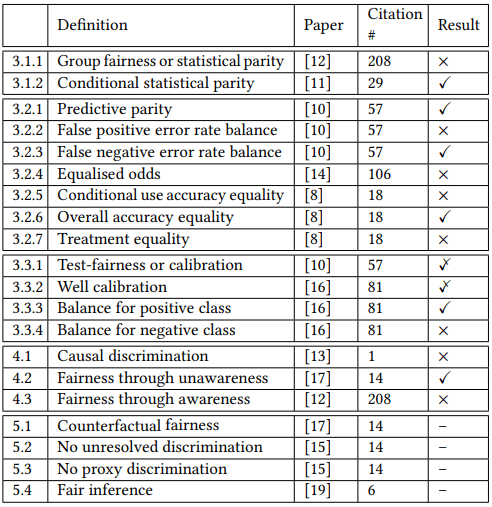
Concluding their assessment of their analysis, they wrote:
So, is the classifier fair? Clearly, the answer to this question depends on the notion of fairness one wants to adopt. We believe more work is needed to clarify which definitions are appropriate to each particular situation.
Saxena et al. (2019), and Srivastava et al. (2019) conducted experiments to find out how public attitudes map to fairness definitions for machine learning. The first paper found calibrated fairness tends to be preferred in the context of loan decisions while the second study found that demographic parity most closely matches people's idea of fairness as applied to criminal risk prediction and skin cancer risk prediction.

While the intentions of the research were right and is an interesting area to explore, the methodology is lacking. Both papers ask respondents sourced through Amazon's mechanical turk to answer a series of questions. As the questions very explicitly mentioned race and gender attributes, respondents are primed to perceive fairness through the lens of a redistributive one. The most one could claim is that if subjects are forced to reason about fairness in a utilitarian cost-benefit setting, they tend to prefer the selected metrics.
The right approach I argue would be to take a more holistic view of what's fair and ethical, before re-introducing the issue of what metrics. In the subsequent sections, I highlight the limitations with the existing approach by pointing out three facts and explore their implications:
- Data as a reflection of ourselves and society
- Models as tools for discrimination
- The difficulty of agreeing on a common definition of what's ethical
Data as mirrors
In a discussion on automated hiring systems and biases3 in the hiring process, Stoyanovich et al. (2020) eloquently warns about the inherent biases of a dataset using an analogy of data as a mirrored reflection of the world:
Informally, data is a mirror reflection of the world. More often than not, this reflection is distorted. One reason for this may be that the mirror itself (the measurement process) is distorted: it faithfully reflects some portions of the world, while amplifying or diminishing others. Another reason may be that even if the mirror was perfect, it may be reflecting a distorted world — a world such as it is, and not as it could or should be.
A data-centric approach is inherently limited, as it lacks information about the context in which it is generated, processed and analysed. Just like how a reflection does not know it is distorted, or why it is distorted, we should not expect the data to know information about itself. While some might think collecting more data might alleviate data issues, the size of the data can be regarded as the size of the mirror - a larger mirror does not mean that the image is less distorted.
Similarly, we cannot expect an algorithm to make a judgement of what is fair or not. While, I shall argue in the subsequent sections that even if the algorithm has complete information about the context in which the data is generated it should still not be able to make such a judgement, the fact that it lacks such historical context and understanding should already be red flags for anyone trying to think that it could.
A dataset forces a particular perspective of reality. It does not tell us what is not captured or other possible alternatives. This is not to say that the reflection observed is not important - it is, but we need to bring in additional perspectives and dimensions to contextualise our understanding.
Models as discriminatory
Every model is discriminatory.4 In the process of trying to optimise against a particular objective function, it tries its best to discriminate against all possible dimensions available in a dataset. This applies to complicated deep neural networks, simpler regression trees and even heuristic models.
In the context of a hiring decision, the model might make a classification based on input features such as test scores, psychometric scores, interviewer ratings and of course age, gender and race. The ability of more complicated models to discriminate is the main rationale for the use of more powerful and deeper machine learning models.
Sometimes it discriminates too much and is not effective in real world applications - i.e. the model has overfitted the dataset. Hence, the use of a hold-out test set to cross-validate the results and ensure it is able to generalize more broadly in world world cases. Nonetheless, left unconstrained, a model will pursue the single goal it is created for, discriminate against all attributes to maximise an objective function, including attributes such as race, gender or religion.
Even if such attributes are omitted, the model would also be able to learn existing attributes in a dataset and its correlation with the protected attributes. Barocas et al. (2019) gives an example of how browsing data might be used differentiate the sexes. While each website provides a small signal, their joint distribution can strongly predict whether a user is male or female.
If models are inherently discriminatory, it is up to humans to decide what should be discriminated against and what is not.5 Relying on a single utility function to determine the tradeoffs between fairness and efficiency seems to be a way of evading responsibility and accountability.
Ethics and Fairness
The debate on ethics, fairness and justice is not new and has been contested by philosophers and political scientists from Plato to Rawls. I will probably not do justice in summarising the nuances in the debate, but I think it's still worth highlighting a few different perspectives to show how standards of what is fair varies.
Before we can dive into the question of what is fair or equitable, we have to ask "fair" by what values or standards?6 The issue of what is right or wrong brings us into the heart of ethics.
Utilitarianism
One way that we could determine whether a particular act is right would be by summing up the benefits and substracting the cost of its associated harms. If the sum of such a measure (utility) across all affected individuals is positive, it is ethically correct.
Intuitively, this definition of act utilitarianism maps most closely to what is possible by the single fairness metric formulation. If we could list out the benefits and harms of every outcome of a models decision, we could create a single utility function that maximises that objective, and in the process of doing so, we maximise social utility.7
Alternatively, we could take a step back and ask what would happen if every person / company were to adopt such a rule or policy, would it be in the best interest of society? This line of reasoning, also known as rule utilitarianism seeks to ground the mathematical formulation of act utilitarianism with some sense of check and balances.
While possibly easier to implement as it relates it AI systems, utilitarianism has major gaps, both practically and morally. Practically, it is nigh impossible to measure benefits and harms across disparate areas (e.g. health vs wealth), or agree on a suitable discount factor to consider the longer lasting effects of policies. Morally, it is hard to be convinced that we should only be concerning ourselves with the consequences of an action and not the action itself. It is also easy to imagine a scenario where a model can be deployed where the benefits to the majority outweigh the harm to a minority class. Morally such as an action would probably strike us as unfair but it would be ethical in a utilitarian framework.
Deontological Ethics
In a utilitarian framework, every consequence can be measured and compared, including the value of a human life. This might strike us as unsettling, not because it is hard to put a price tag to life, but just because we think that human life should not be valued and compared. For an AI self-driving car, when faced with a decision of serving to save a life, it should not be calculating the resulting damage and weighing it against the value of a human life. Instead, it should serve, just because saving a life is the right thing to do.
Such a way of thinking falls squarely in the realm of duty ethics or deontology. Some choices cannot be justified by their effects, no matter how good their consequences are - right takes priority over good.
While there are variations within the deontological ethics community such, whether to focus on an agent's duties or a victim's rights, they share in common a belief as espoused by Kant (1785) that the only thing unqualifiedly good is a good will.8
For the rest of human decision making that does not classify as moral decisions, there is no categorical imperative to do anything associated about it.9 This seems like a more sane basis to ground our decision making process on and seems to be more aligned with moral intuitions of society in general. Practically, this translates to a different way of evaluating models - if the system does not make decisions that contradict what we believe as categorical imperatives then there is no reason not to give the machine the flexibility to optimize.
Virtues
Instead of thinking about what goodness and ethics might mean for a machine, we can ask what are the characteristics of a good person. Through that lens, we might say that a person is ethical if he lives by certain traits or virtues which one might regard as morally good.
The apparent simplicity and practicality of such a system of morality are also its greatest strengths. Foot (1997) in Virtue and vices, lists three essential feature of a virtue:
- It's a disposition of the will
- It's beneficial to others, or to its possessor as well as to others
- It is corrective of some bad general human tendency
This list might correspond to virtues like Aristotle's Nicomachean Ethics which includes values such as Courage, Magnanimity and Truthfulness, or it could correspond to theological values of the church - Faith, Hope and Charity.
In this age of technology and automation, Vallor (2016) argues that virtue ethics can be a shining beacon that guides decision makers in techno-sociological choices as it is "ideally suited for adaptation to the open-ended and varied encounters with particular technologies that will shape the human condition in this and coming centuries". While agreeing on a common standard of shared virtue ethic might be a herculean task, it is not unreasonable to expect companies and individuals to have a set of core values that they believe in, and would form the basis of evaluating the impact of AIDA models.10
One might ask, how would it be possible to embed moral virtues in an artificial intelligence system and question whether that can be operationalised. Rather than expecting a system to learn a set of values, I think it makes more sense to ask whether the outcomes produced by these systems conform to our internal values. Instead of asking whether a gun is ethical, we should ask in what context and what circumstances is the use of a gun ethical.
Operationally, instead of calculating the expected utility of benefits and harms, these benefits and harms could be presented to an internal review board and accessed based on a set of virtues. If the organisation has virtues such as justice, empathy or care on their checklist, they would be able to flag out a scenario where the majority benefits at the expense of a minority group. If such values are not present, we can then turn the discussion towards the values of an organisation, rather than to talk about AI values which is a pointless exercise.
Practical Ethics
The discussion above on three popular ethical schools of thought is not meant to promote one over the other. Practically, human beings have a deeply complex value and judgement system which might not even be internally consistent. In certain cases, one might adopt a utilitarian point of view, in other situations, we might choose to adhere to certain religious principles and beliefs.
One thing it does show is that what is ethical or not can be highly contentious and we should not restrict ourselves to a single metric in trying to categorise what is right or wrong. Not only is it incapable of capturing the crux of ethical arguments put forth in such debates, but it also artificially restricts us to a set of measures that might not map to what society perceives as ethical.
Next, we turn our attention to the issue of fairness since it is often brought up in discussions on AI governance. We have already seen it mentioned in the above section on virtue ethics and one might claim that we ought to be fair in the application of AI systems, but what do we exactly mean by fairness?11
Fairness
Aristotle's principle of equality states that:
equals should be treated equally and unequals unequally.
The quote suggests that individuals should be treated the same, unless they differ in ways that are relevant to the situation in which they are involved. For example, if both Jack and Jill can do the work to the same standard, they should have the same chance of being hired. If Jack has a higher chance of being hired just by being a man, we can say that it is a case of unfair hiring.
However, the principle of equality does not take into account individual differences that play a part in explaining one's circumstances. In the context of hiring, the opportunities available to women might vary significantly from those available to a man. These differences accumulate over time and translate to differences in work output, even if both men and women were initially equally capable and talented at birth. One might argue that fairness, in this case, is equity - everyone should have equal access to the same opportunities.12
Fairness in AI systems
In the context of AI decision making systems, concepts of equality or equity deserve additional scrutiny. The metrics that are used to determine what is fair or not, are statistical measures that are derived based on the observed and collected data. Despite the seemingly numerous ways in which one can derive such metrics of fairness, these measures take the state of the world as given, rather than as constructed.13
If that is the case, it would be better to name these measures as "equivalence metrics" rather than "fairness metrics" as they do not map to an ethical sense of fairness. We can ask whether the number of males and females recommended by our AI model is the same or if the estimated false positive or false negative rates are equivalent, but not whether the model is actually fair. Fairness requires situating the equivalence metric in the context that it is being applied, understanding historical or structural factors that could possible explain the differences and a value judgement based on some ethical reasoning.
Another benefit of using the term equivalence rather than fairness is that many of these measures are simply incompatible. Degenerate solutions notwithstanding, mathematically, as formulated in a classification problem, one cannot have equivalence across classes in the number of predicted positives as well as equivalence in the false positive or false negative rates.14 More broadly, how we think about fairness varies across scenarios, but given a specific problem, we can probably articulate why we think a particular distribution or outcome is fair.15
A lot of what is discussed in the machine learning literature touches on fairness (or rather equivalence in certain outcomes) between groups, yet this narrowly constricts fairness to the notion of equality. Of course, we should think about fairness in the context of prejudiced groups, but we should also ask whether it is fair to an individual. Adding constraints in models might lead to worse outcomes for other individuals. If the decision making processs has serious consequences e.g. a fraud model, it is hard to think that we are truly fair by forcing models to obtain an equal number of fraud cases across certain demographic attributes.
Practically, we should be flipping the approach. One should first ask what fairness means in a given scenario before mapping it to a numerical measure, if applicable. In the case of hiring decisions, where AI is used as a pre-selection step, we might think shortlisting an equal proportion of males and females is fair. While in the case of fraud prevention models, fairness probably means getting the best result for each subgroup by reducing the false positive rate for each group as low as possible and not artificially trying to make them equal!
Conclusion
In this post, I question the rationale of fairness metrics as presented in the AI and machine learning literature. I argue that given the nature of data as (distorted) reflections of society, of models as unthinking agents of discrimination (in the broadest sense of the word), we should evaluate such systems from a human-centric perspective.
While there is much debate within ethics on what constitutes right and wrong, by using it as a starting point of our decision-making process, we re-introduce human decision making to a process that should be governed by humans. Instead of absconding from our human responsibility on making informed decisions and leaving it to conflicting mathematical definitions of "fairness", we should instead ask - what does fairness mean in a given context and how does the outcome affect individuals and the broader society.
References
Footnotes
There are other open-source solutions as well and I will address the differences in the next post, but this post should give a flavour of what we are going to do differently. ↩
e.g. accuracy or area under ROC curve for a binary classifier or root mean square error for a continuous outcome ↩
The word bias in this post should be understood in the social justice sense and not as the statistical concept ↩
Discriminatory is used over here in the sense of being able to differentiate, not in the social or legal sense of the word. ↩
I think there's no lack of a human's ability to discriminate as well, we do it every day. There just seems to be a fear when it comes to making such discriminations explicit. ↩
Could something be fair but unethical or unfair but ethical? It lies very much in the definition of the terms, but here are examples of each. One could argue that as a system for justice "an eye for an eye" is fair but unethical. On the other hand, treating people with different vaccination statuses differently would probably be unfair but ethical. ↩
In the case of a binary classifier, we can assign a score to each potential outcome (true positive, false positive, true negative and false negative) and use the scores as part of the objective function. ↩
Differing definitions on what a good will is gives us different Kantian schools of thought. ↩
It might be morally praiseworthy but that's no categorical ought. ↩
The list of values proposed by Vallor could be a good start: honesty, self-control, humility, justice, courage, empathy, care, civility, flexibility, perspective, magnanimity, and technomoral wisdom. ↩
In a utilitarian framework, fairness could simply arise if we assume individuals have a utility function which exhibits diminishing marginal utility. ↩
E.g. Affirmative action policies and wealth redistribution policies are examples of how a society might try to mitigate existing unfair biases. To what extent are the policies sufficient to achieve equity is another question. ↩
An exception is the counterfactual school of thought which requires constructing a causal graph which describes the relationships between particular variables, observed or unobserved, and mapping a definition of fairness based on hypothesised pathways and relations. ↩
See Barocas et al. (2019) for a proof of independence versus separation. ↩
Note, this refers to one outcome, not 20 different fairness outcomes. ↩