- Published on
Notes on Regression - Projection
- Authors
- Name
This is one of my favourite ways of establishing the traditional OLS formula. I remember being totally amazed when I first found out how to derive the OLS formula in a class on linear algebra. Understanding regression through the perspective of projections also shows the connection between the least squares method and linear algebra. It also gives a nice way of visualising the geometry of the OLS technique.
This set of notes is largely inspired by a section in Gilbert Strang's course on linear algebra.^[My two favourite sources covering the basics of linear algebra are Hefferon's linear algebra, a free textbook, and Gilbert Strang's course mentioned above. Hefferon provides a very clear treatment on the more theoretical aspects of the subject, while the latter highlights the many possibilities and applications that one can do with it.] I will use the same terminology as in the previous post.
Recall the standard regression model and observe the similarities with the commonly used expression in linear algebra written below:
Thus, the OLS regression can be motivated as a means of finding the projection of on the space span by .^[The span of the vectors in (column space) is the set of all vectors in that can be written as linear combinations of the columns of ] Or to put it another way, we want to find the vector that would be the closest to .
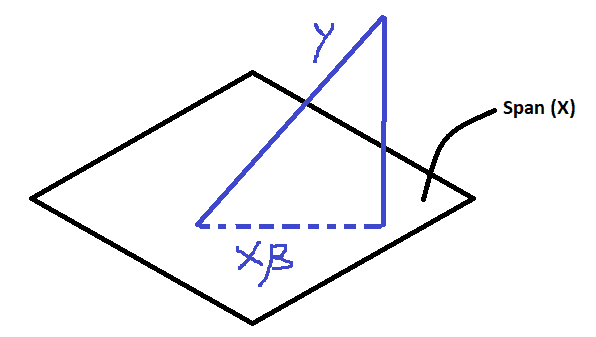
Notice that is orthogonal to i.e. it is in the left nullspace of . By the definition of nullspace:
Notes:
is also known as the orthogonal projection matrix. The matrix is dimension. As given by its name, for any vector , .
is simply the vector of residuals and can be written in the following form:
is the projection onto the space orthogonal to .
- The projection matrices have the following four properties: , Symmetry (), Idempotent (), Orthogonal ().
Additional Comments:
The idea of seeing fitted values and residuals in terms of projections and orthogonal spaces have further applications in econometrics. See for example the derivation of the partitioned regression formula.
As a fun exercise one can try to derive the OLS formula for a weighted regression where is an matrix of weights using the same idea.