- Published on
TraceTogether and the Difficulty of Graph Anonymisation
- Authors

- Name
- Timothy Lin
- @timlrxx
This article is written in response to the recent TraceTogether privacy saga. For the non-Singaporeans out there, TraceTogether is Singapore's contact tracing initiative in response to the COVID-19 pandemic in Singapore. The objective of the program was to quickly identify people who might be in close contact with anyone who has tested positive for the virus. It comprises of an app or physical token which uses Bluetooth signals to store proximity records. As at the end December 2020, 70% of Singapore residents were supposedly on the programme.
On 4 January 2021, it was revealed that TraceTogether data may be used by the police for criminal investigations. This led to some clarifications from the ministers in-charge and a greater debate surrounding privacy concerns of the programme. The Minister of Home Affairs clarified that under the Criminal Procedure Code (CPC), police can and has used TraceTogether data to investigate "serious crimes, like murders or terrorist incidents". The privacy statement on the TraceTogether website was subsequently modified to clarify this point.
Subsequently, a bill was passed to restrict the use of TraceTogether data for serious crimes. It clarified on the use of data post-pandemic and mentioned that anonymised data may be retained for the purpose of epidemiological research to "strengthen our public health response":^[https://www.straitstimes.com/singapore/proposed-restrictions-to-safeguard-personal-contact-tracing-data-will-override-all-other]
Minister Vivian Balakrishnan had also brought up that possibility in an earlier parliamentary statement:
But I believe that once the pandemic has passed, that data – certainly, the specific, personalised data – those fields should be eliminated. For research purposes, I believe MOH may want to still have epidemiologic data but it should be anonymised. It should not be personalised, it should not be individualised.
Source: https://sprs.parl.gov.sg/search/sprs3topic?reportid=clarification-1547
While anonymised epidemiological data could potentially be very useful for future studies, there are two reasons why one should re-consider such a decision.
It is a scope creep of the intended purpose of TraceTogether from contact tracing operations to police enforcement to research.
Given the nature of the TraceTogether programme, it would be extremely difficult to strike a right balance between anonymity and usefulness even of "anonymised" data. This is because proximity data is essential a network of connections and the insights that can be drawn from the connections also make it possible for an adversary to de-anonymise it.
The use of anonymised data for research has either flown under the radar or there is just not enough awareness of the risk of de-anonymisation, especially of network data. The word "anonymised data" seems to convey a certain sense of certainty that user information cannot be back-derived. As a data scientist working in the space of network science, this is far from the truth and I wish to take this space to explain the difficulties of network anonymisation.
Why anonymise?
Data anonymisation is the process of protecting private or sensitive information by erasing or encrypting identifiers while preserving the usefulness of the data for research purposes.
Anonymisation is a trade-off. We can achieve 100% privacy by substituting every field of our dataset of interest with random values, but that would render the data to be totally useless. Hence, Statisticians have researched different data anonymisation techniques including masking, permuting, perturbation or synthetic data creation, with the goal of balancing privacy and usefulness.
A simple reidentification technique
Let's start with a simple tabular dataset to illustrate why removing or masking Personally Identifiable Information (PII) fields do not help achieve privacy. We start with a sample raw dataset that takes the following form:
| id | name | address | sex |
|---|---|---|---|
| 1 | A | 123 | M |
| 2 | B | 123 | F |
| 3 | C | 456 | F |
Here's the dataset with id and name masked, with rows shuffled:
| id | name | address | sex |
|---|---|---|---|
| xx | xx | 456 | F |
| xx | xx | 123 | F |
| xx | xx | 123 | M |
How can we find out the identity of each of the records? Let's suppose we have an external census dataset with information on address, sex and name, and that each combination of address, sex and name is unique. With this, we can do a join on our "masked" dataset using the address and sex fields to decipher the name field. Here, we rely on the fact that there's a 1 to 1 mapping between the combination of address and sex with the name field.

Source: Garrick Aden-Buie's Tidy Explain
The sparsity of the dataset affects how easily and accurately an adversary could conduct a "join attack". If we only have one field in the dataset e.g. address, we would not be able to identify each person uniquely since there are two individuals with 123 as address. The 'problem' with real-world datasets is that it is relatively easy to find unique combination of variables that could lead to an individual being identified.
Unraveling identity - 2 examples
GIC
In the 1990s, a Massachusetts government agency known as the Group Insurance Commission (GIC) decided to release records summarising every state employee’s hospital visits to any researcher who requested them. Explicit identifiers such as name, address, and social security number were removed but hospital visit information such as ZIP code, birth date, and sex was included.
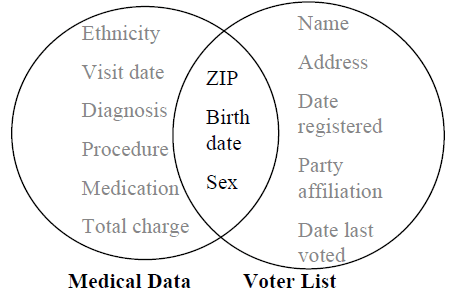
Sweeney
1997
showed that the GIC data could be joined with voter rolls to uncover masked PII information. In an interesting twist to the story, Dr Sweeney sent William Weld the then−Governor of Massachusetts who assured the public that GIC had protected patient privacy by deleting identifiers his health records. Based on the 1990's census data, he discovered that 87% of American citizens were uniquely identified by their ZIP code, birth date, and sex. More recent studies suggest a lower but still significant figure of 63% (
Golle
2006
)
Netflix data
More recently, the movie scoring data released by Netflix as part of an open competition held to find the best recommendation system has been shown by Narayanan and Shmatikov 2008 to be not as anonymised as initially thought. How much does an adversary need to know about a Netflix subscriber in order to identify her record if it is present in the dataset, and thus learn her complete movie viewing history? As it turns out, not that much.
84% of subscribers present in the dataset can be uniquely identified if one knows 6 less popular movie ratings (outside the top 500). Using an auxillary dataset of personal movie ratings scraped from IMDb, they showed that it is possible to de-anonymise a few users with high probability.
The ties that bind
Let's assume that there are no plans to keep any individual information. Instead, only proximity information is retained for analysis.1 Would this slice of information be a threat for re-identification?
Yes, research and experiments on social media data have shown that information on connections could reveal hidden ties that connect users. To illustrate this, we transform proximity data into a graph form. A graph (also known as a network) is a data structure consisting of nodes / vertices connected together by edges / links. Graph structures are present in everyday life from road connections to social networks to . . . proximity data.
Proximity data could be thought of as an edge-list. For an individual A, we construct a link to another individual B if A and B are recorded in the same proximity window.
Let's ignore the time element of the problem and assume we have our hands on the following connection dataset which represents the link between two individuals masked with an index number.2
| from | to |
|---|---|
| 2 | 1 |
| 3 | 1 |
| 4 | 1 |
| 5 | 1 |
| 6 | 1 |
| 7 | 1 |
| 8 | 1 |
| 9 | 1 |
| 10 | 1 |
| 11 | 1 |
| 9 | 10 |
| 11 | 9 |
| 11 | 10 |
For example, in our table, individuals 2 and 1 are connected. The data could be visually represented by the following graph:
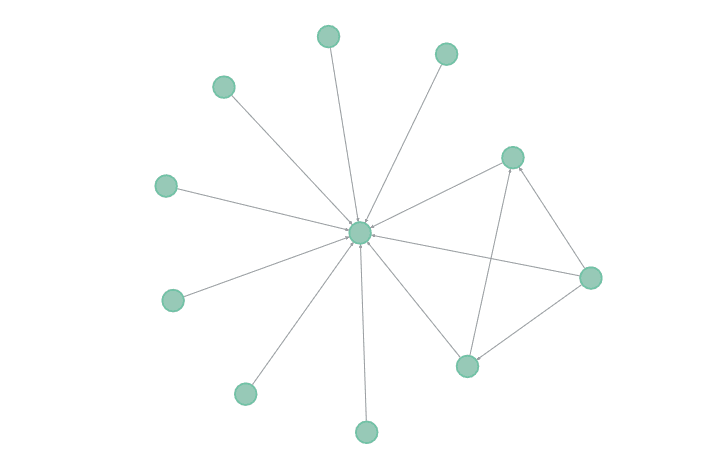
What features or attributes can we infer from the graph? We would be able to calculate the number of connections of each individual (also known as the degree). For example, individual 1 has 10 neighbours while individual 10 has 3 neighbours. Suppose we have a leak of the full connections dataset which can be plotted below:
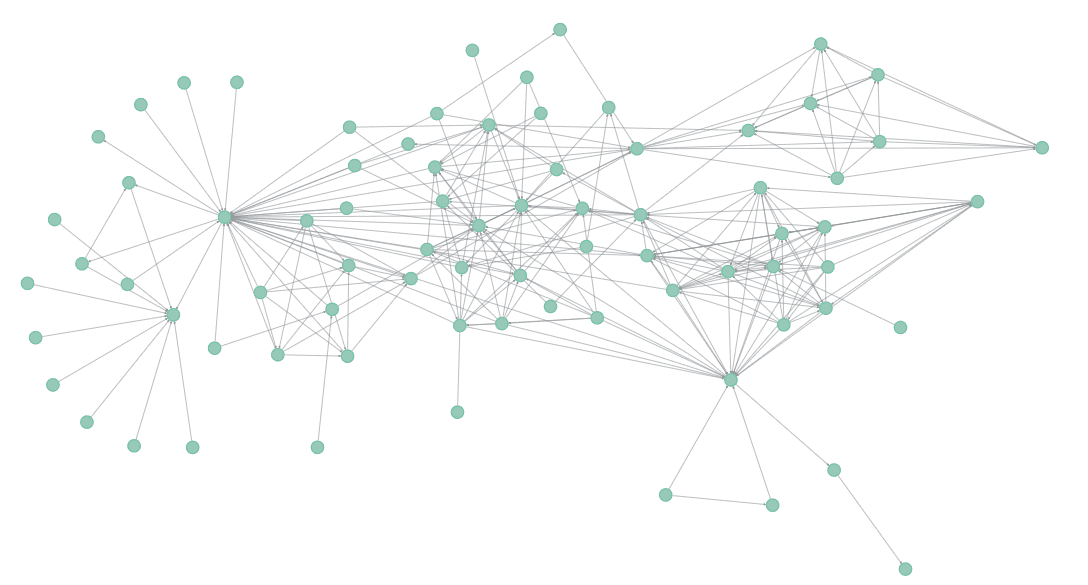
The challenge of de-anonymisation is simply trying to find a segment of the full graph that "matches" our subgraph (more formally known as the subgraph matching or subgraph isomorphism problem). Are you able to find it?
Let me help by colouring the clusters and it should be pretty obvious. Click the footnote to reveal the answer.3

The above network is a graphical representation of the frequently used Les Miserables network dataset. Our subgraph is Myriel's ego network (Myriel and all her connections). As it turns out there are only 5 individuals in the graph with 10 connections. This helps to significantly shrink the pool of candidate matches. Listing out individuals with the most connections in descending order we get:
| Name | No. of Connections (Degree) |
|---|---|
| Valjean | 36 |
| Gavroche | 22 |
| Marius | 19 |
| Javert | 17 |
| Thenardier | 16 |
| Enjolras | 15 |
| Fantine | 15 |
What can we learn from this example?
- It is easy to generate node / entity level features from edge attributes
- Due to the nature of social interactions, these features tend to exhibit large variations and outliers
- Anonymity of social networks is not sufficient for privacy
In another landmark paper, (Narayanan and Shmatikov 2009) demonstrated the effectiveness of a network topology based re-identification algorithm on real-world social media datasets. They showed that members of Flickr and Twitter can be recognized in a completely anonymous Twitter graph with only 12% error rate, even though the overlap in the relationships for these members is less than 15%. Since their paper, Twitter has introduced a rate limitation on their API which makes large scale crawling and scraping infeasible.
Anonymity through obfuscation
One approach to make such anonymisation attacks more difficult is to obscure or obfuscate relationship information. For example, one could perturb edge information so as to introduce some probabilistic uncertainty of each connection. Alternatively, we can remove connections from highly connected people to make them blend in with normal individuals. Doing so would however remove our ability to analyse super-spreaders or the risk of viral spreading among front-line workers (these workers would be highly connected as they meet significantly more people a day). As mentioned previously, data anonymity is a trade-off and here we tip the scales more in favour of privacy over research.
The many paths to de-anonymisation
Surprisingly, such anonymisation methods do not totally remove the risk re-identification. So far we have only considered obscuring the degree distribution in the data, but there are other metrics that could be constructed from a graph dataset. We could have calculated the number of connections which are two hops away (neighbour of neighbour), or the number of triangles passing through each node in the graph, or a measure of centrality such as the Pagerank score. There are numerous measures that capture different aspects of the network and how a node fits within that network. Obfuscating one metric does not necessarily imply that other metrics are equally anonymised.
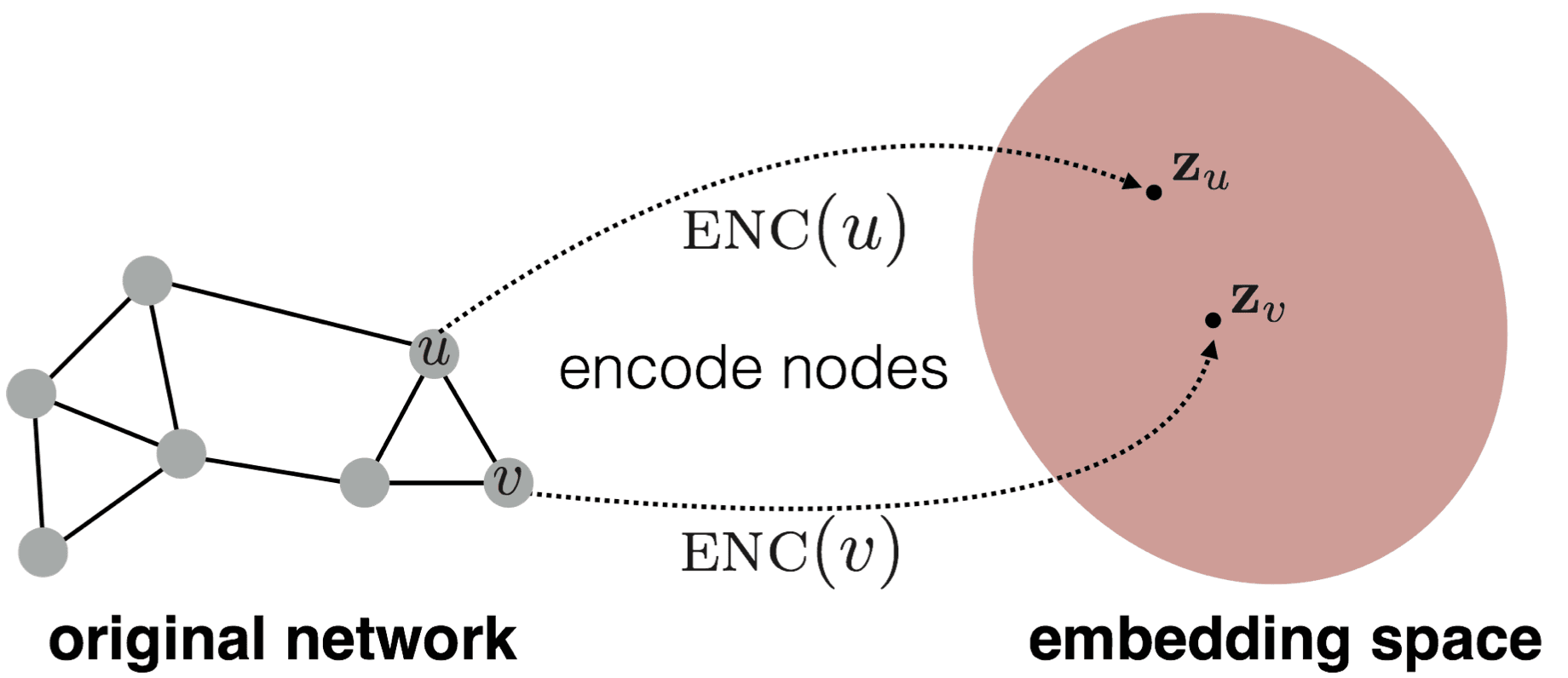
Source: Jure Leskovec's cs224w notes
How can we summarise the "essence" of a node by taking into account all its neighbouring relationship and its position in the entire network space? Node embeddings (Grover and Leskovec 2016), a relatively new application of neural networks on graph data structures seek to do just that by mapping the relationship of nodes into a lower dimensional vector space.
Nodes that are closer together in the embedding space are more similar in the original network.4 Given an anonymised network dataset, we can calculate the embedding of each node and derive the likelihood of each node being actually connected to a given node on the true dataset. The more features we obscure and obfuscate, the less accurate is the de-anonymisation rate.
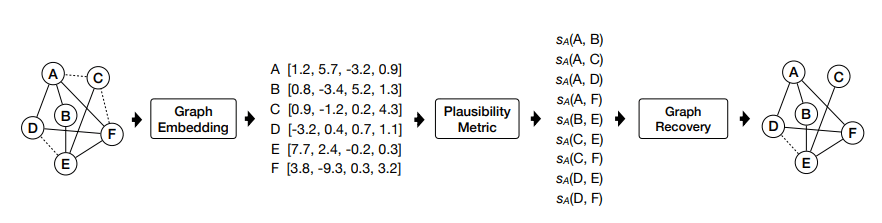
Source: Zhang et al. 2017
Importantly, we can use node embeddings to quantify an edge's plausibility and use that information to recover the original dataset. Zhang et al. 2017 exploited this vulnerability to recover the original graph of three test datasets which were anonymised by using different graph anonymisation techniques. They proposed methods to improve existing techniques by adding fake edges which are more similar to the edges in the original graph. Though this made it harder to recover the original dataset, they note that it is "non-trivial to create fake edges totally indistinguishable from original edges".
Connecting the dots
What are the ingredients necessary for such a privacy attack?
- An "anonymised" network dataset
- Seed information that could compromise the identity of one or more individuals
- A subgraph with ground truth information
Even if the TraceTogether data is compromised, surely it is hard to find attack vectors 2 or 3? Not quite, all it requires is a little imagination and creativity as shown by the various research papers. In fact, information on subgraphs is readily available in the form of the BluePass programme:
BluePass includes contact tracing tokens used by migrant and local workers living or working in dormitories, as well as those in the construction, marine shipyard and process sectors. The BluePass tokens are compatible with the TraceTogether token or app, which means they can exchange information with one another.
A crucial difference is that employers have the oversight of the data in these devices to allow them to more quickly quarantine close contact of Covid-19 cases.^[https://www.straitstimes.com/tech/tech-news/special-contact-tracing-devices-for-singapore-workers-in-sectors-with-flammable-gas] They can access BluePass data of their own employees but not of other BluePass tokens or TraceTogether data.
Even though the new bill covers both TraceTogether and BluePass, and there are strict penalties in place for unauthorised use or disclosure of contact tracing data, one wonders how secure are the cybersecurity practices of the companies handling this data. Since the bill does not cover anonymised data, companies could retain de-anonymised BluePass data for their own internal research as well. Any leaks or breaches of the various BluePass datasets could compromise the identity of the workers and possibly even the anonymised TraceTogether data.
Summary
In this article, I examined the difficulties of graph anonymisation. I showed how re-identification could be done on tabular data even if PII information is masked and extended the analysis to network datasets. Connections between nodes contain a lot of information and can be used as the basis of a re-identification or graph recovery attempt. Attempts to perturb or mask edge information is difficult and it is hard to strike a balance between usefulness and privacy.
I also outlined how an adversary could potentially perform a graph recovery attack on anonymised TraceTogether data using data derived from the BluePass program.
To stay on track with the use of the TraceTogether program as a means to tackle Covid-19 (and possibly other future pandemics), two changes should be made. One, only aggregated but not anonymised data should be retained. Two, companies should be legally obligated to delete BluePass data or hand it over to the MOH upon the end of the pandemic.
References
Golle, P. "Revisiting the uniqueness of simple demographics in the US population." Proceedings of the 5th ACM Workshop on Privacy in Electronic Society. pp. 77-80. 2006.
Grover, Aditya, and Jure Leskovec. "node2vec: Scalable feature learning for networks." Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining , pp. 855-864. 2016.
Narayanan, Arvind, and Vitaly Shmatikov. "Robust de-anonymization of large sparse datasets." 2008 IEEE Symposium on Security and Privacy (sp 2008) , pp. 111-125. IEEE, 2008.
Narayanan, Arvind, and Vitaly Shmatikov. "De-Anonymizing Social Networks." 2009 30th IEEE Symposium on Security and Privacy , pp. 173-187. IEEE, 2009
Sweeney, L. "Weaving technology and policy together to maintain confidentiality." J. of Law, Medicine and Ethics 25, no. 2-3 (1997): 98-110.
Zhang, Yang, Mathias Humbert, Bartlomiej Surma, Praveen Manoharan, Jilles Vreeken, and Michael Backes. "Towards plausible graph anonymization." arXiv preprint arXiv:1711.05441 (2017).
Footnotes
It could be argued that researchers only need access to proximity data rather than individual identifiers for research on transmission and effectiveness of safe distancing measures. ↩
The time element if not masked would just increase the dimensionality of the dataset, making it easy to re-identify an individual. ↩
Answer: blue cluster on the left ↩
Similarity can be defined in various ways e.g. adjacency or paths. ↩